자바는 OS 에 독립적인 특징을 가지고 있다.
JVM 이 OS 와 프로그램의 사이에서 기계어로 해석해주는 역할을 한다.
JVM
컴퓨터가 어떤 프로그램을 실행하려면, 그 프로그램이 컴퓨터의 언어(기계어)로 작성되어야 한다.
하지만 우리는 복잡하고 해석하기 어려운 기계어를 직접 작성하지 보다는 코드를 작성한다.
- 컴퓨터가 이해할 수 있는 기계어로 변환해주는 역할
- 어떤 운영체제에서도 Java 코드가 실행될 수 있도록 해주는 것
- 컴파일된 바이트 코드를 기계가 이해할 수 있는 기계어로 반환
- 스택 기반의 가상 머신
- 메모리관리와 GC를 수행
자바 코드 실행과정

- 개발자가 자바코드를 작성한다.
- .java 인 파일을 자바 컴파일러를 통해 자바 바이트 코드로 컴파일한다.
- 바이트 코드 : JVM 에서 작동하도록 만든 이진코드
- 즉, JVM 이 이해할 수 있는 언어로 변환된 코드
- 명령어의 크기가 1바이트라서 자바 바이트 코드라고 불리고, 자바 코드를 배포하는 가장 작은 단위
- 컴파일 된 바이트 코드를 JVM 의 Class Loader 에 전달한다.
- Class Loader 는 동적 로딩을 통해 필요 클래스들을 로딩 및 링크하여 RunTime Data Area 에 올린다.(JVM의 메모리)
- 실행 엔진은 JVM 메모리에 올라온 바이트 코드들을 명령어 단위로 하나씩 가져와서 실행한다.
❗️용어 정리
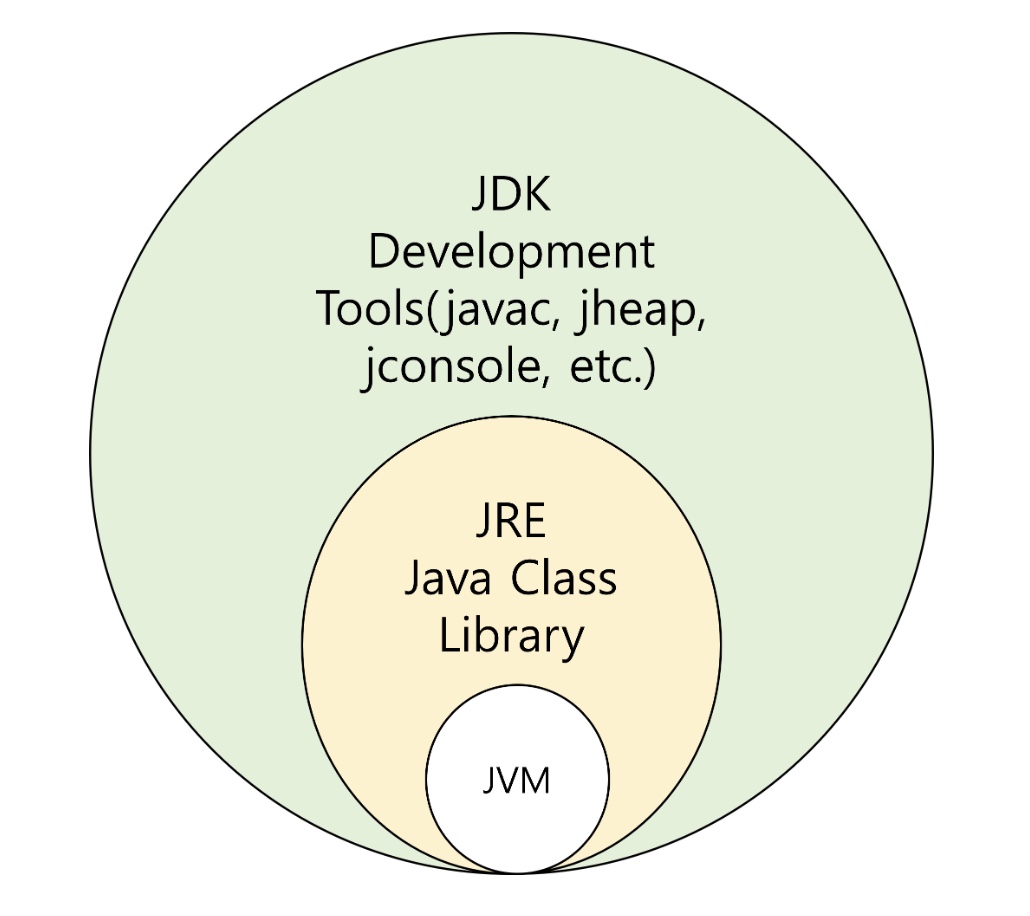
JVM : 자바 가상환경으로서 컴파일러를 통해 나온 결과를 바이트 코드로 실행시켜주는 가상머신
JRE : Java Runtime Environment 의 약자로, 자바 실행환경을 의미. 실행에 필요로하는 각종 라이브러리를 담고 있다.
JDK : Java Development Kit 의 약자. 자바 개발 키트를 의미
JVM 구조

JVM 의 구조는 크게 GC(Garbage Collector), Execution Engine, Class Loader, Runtime Data Area 4가지로 이루어져 있다.
GC - Garbage Collector
- 힙 메모리 영역에 생성된 객체들 중 더 이상 참조되지 않는 객체를 자동으로 검색해 제거한다.
- 이때, GC가 역할을 하는 시간은 언제인지 정확히 알 수 없다.
- GC가 수행되는 동안 GC를 수행하는 쓰레드가 아닌 다른 모든 쓰레드가 일시정지된다
- 만약 Full GC가 일어나서 수 초간 모든 쓰레드가 정지한다면 장애로 이어지는 치명적인 문제 발생 가능성있다
실행 엔진 - Execution Engine
- 메모리에 적재된 바이트코드(.class)를 기계어로 변환해 명령어 단위로 읽어 실행하는 역할
- 위와 같은 역할을 수행하기 위해 2가지 방식이 사용된다.
인터프리터
- 바이트코드(.class)를 한 줄씩 읽어서 실행한다.
- 하지만 같은 코드를 실행할 때마다 바이트코드를 매번 해석해야해 속도가 느리다는 단점이 있다.
JIT(Just In Time Compiler) 컴파일러
- 인터프리터의 단점을 보안하기 위해 도입된 것
- 프로그램 실행 중에 바이트코드 전체 또는 일부를 네이티브 코드로 컴파일하고, 직접 실행한다.
- 이 방식은 초기 컴파일에는 시간이 걸리지만, 한 번 컴파일된 코드는 매우 빠르게 실행된다.
- 또한 JIT 컴파일러는 자주 실행되는 코드를 분석해 우선적으로 컴파일하여 성능을 최적화한다.
⇒ 설명만 봤을 때는 JIT 컴파일러만 사용할 것 처럼 보이지만 JVM 실행 엔진에서는 이 2가지 방식을 함께 사용
⇒ 프로그램 실행 초기에는 인터프리터 방식으로 빠르게 시작하고 실행 중에 JIT 컴파일러가 분석을 통해 성능이 중요한 부분을 식별해 네이티브 코드로 컴파일한다.
클래스 로더 - Class Loader
- JVM 내로 클래스 파일을 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈
- 자바 컴파일러에 의해 생성된 클래스파일들을 엮어서 JVM이 운영체제로부터 할당받은 메모리영역인 Runtime Data Area로 적재하는 역할을 Class Loader가 한다.
- 자바 애플리케이션 런타임시에 수행된다.
런타임 데이터 영역(Runtime Data Area)

- JVM 이 운영체제 위에서 실행될 때, 할당 받는 메모리 영역으로 다음과 같이 분류 된다.
- Method 영역과 Heap 영역은 모든 쓰레드에서 공유되고, 나머지 영역을 쓰레드마다 각각 존재한다.
- 영역은 크게 Method Area, Heap Area, Stack Area, PC Register, Native Method Stack로 나눈다
Method 영역

- JVM 이 시작될 때 생성되는 공간으로 바이트 코드(.class)를 처음 메모리 공간에 올릴 때 초기화되는 대상을 저장하기 위한 메모리 공간
- JVM 이 동작하고 클래스가 로드될 때 적재되서 프로그램이 종료될 때까지 저장된다.
- 모든 쓰레드가 공유하는 영역이라 다음과 같은 초기화 코드 정보들이 저장된다.
- Field Info : 멤버 변수의 이름, 데이터 타입, 접근 제어자의 정보
- Method Info : 메소드 이름, return 타입, 함수 매개변수, 접근 제어자의 정보
- Type Info : Class 인지 Interface 인지 여부 저장, Type 의 속성, 이름 Super Class 의 이름
Heap 영역
- 메서드 영역과 함께 모든 쓰레드가 공유
- JVM 이 관리하는 프로그램 상에서 데이터를 저장하기 위해 런타임 시 동적으로 할당하여 사용하는 영역
- 즉, new 연산자로 생성되는 클래스와 인스턴스 변수, 배열 타입 등 Reference Type 이 저장되는 곳
- Stack 영역과 다르게 보관되는 메모리가 호출이 끝나더라도 삭제되지 않고 유지된다.
- 유의할 점
- 힙 영역에 생성된 객체와 배열은Reference Type으로서, JVM 스택 영역의 변수나 다른 객체의 필드에서 참조된다는 점
- 즉, 힙의 참조 주소는 "스택"이 갖고 있고 해당 객체를 통해서만 힙 영역에 있는 인스턴스를 핸들링할 수 있는 것이다.

- 만일 참조하는 변수나 필드가 없다면 의미 없는 객체가 되기 때문에 이것을 쓰레기로 취급하고 JVM은 쓰레기 수집기인Garbage Collector를 실행시켜 쓰레기 객체를 힙 영역에서 자동으로 제거된다
- 이처럼 힙 영역은 가비지 컬렉션에 대상이 되는 공간이다.
Stack 영역
- int, long, boolean 등 기본 자료형을 생성할 때 저장하는 공간
- 임시적으로 사용되는 변수나 정보들이 저장되는 영역
❗️데이터의 타입에 따라 스택과 힙에 저장되는 방식이 다르다는 점
- 기본(원시)타입 변수는 스택 영역에 직접 값을 가진다.
- 참조타입 변수는 힙 영역이나 메소드 영역의 객체 주소를 가진다.
⇒ 예를 들어 Person p = new Person(); 과 같이 클래스를 생성할 경우, new 에 의해 생성된 클래스는 Heap Area 에 저장되고, Stack Area 에는 생성된 클래스의 참조인 p 만 저장됨
- 스택 영역은 각 스레드마다 하나씩 존재하며, 스레드가 시작될 때 할당된다.
- 프로세스가 메모리에 로드 될 때 스택 사이즈가 고정되어 있어, 런타임 시에 스택 사이즈를 바꿀 수는 없다.
- 만일 고정된 크기의 JVM 스택에서 프로그램 실행 중 메모리 크기가 충분하지 않다면 StackOverFlowError가 발생하게 된다.
- 쓰레드를 종료하면 런타임 스택도 사라진다.
지금까지의 메소드, 힙, 스택 영역을 한 그림으로 표시하면 다음과 같다.

PC 레지스터 영역 - Program Counter Register
- 쓰레드가 시작될 때 생성되며, 현재 수행중인 JVM 명령어 주소를 저장하는 공간
- JVM 명령의 주소는 쓰레드가 어떤 부분을 무슨 명령으로 실행해야할 지에 대한 기록을 가지고 있다.
- 만약, 쓰레드가 자바 메소드를 수행하고 있으면 JVM 명령의 주소를 PC Register 에 저장한다.
- 그러다 만약 자바가 아닌 다른언어(C언어, 어셈블리)의 메소드를 수행하고 있다면, undefined 상태가 된다.
- 왜냐면 자바에서는 이 두 경우를 따로 처리해서이다.
- 이 부분이 Native Method Stack 공간이다.
네이티브 메서드 스택 - Native Method Stack
- 자바 코드가 아닌 실제 실행할 수 있는 기계어로 작성된 프로그램을 실행시키는 영역
- 자바 이외의 언어(C, C++, 어셈블리 등)로 작성된 네이티브 코드를 실행하기 위한 공간
- 위에 나왔던 JIT 컴파일러에 의해 변환된 Native Code 역시 여기에서 실행된다고 보면된다.

- 일반적으로 메소드를 실행하는 경우 JVM 스택에 쌓이다가 해당 메소드 내부에 네이티브 방식을 사용하는 메소드가 있다면 해당 메소드는 네이티브 스택에 쌓인다.
- 그리고 네이티브 메소드가 수행이 끝나면 다시 자바 스택으로 돌아와 다시 작업을 수행한다.
- 그래서 네이티브 코드로 되어 있는 함수의 호출을 자바 프로그램 내에서도 직접 수행할 수 있고 그 결과를 받아올 수도 있는 것이다.
참고블로그
'1일1복습' 카테고리의 다른 글
| [스프링] Spring 과 Spring Boot 의 차이 (0) | 2024.05.16 |
|---|---|
| [DB] 인덱스(Index) - 개념, 장단점, 인덱스의 자료구조 (1) | 2024.05.15 |
| [디자인 패턴] MVC 패턴 (0) | 2024.05.13 |
| [Git] git 영역과 상태 용어 정리 (0) | 2024.05.12 |
| [자바] 접근제어자 (0) | 2024.05.11 |